Enabling Faster than Realtime Training of an AI Scheduler
Training a machine learning (ML) model commonly utilizes a set of trainings data and test data, which are representative of the data the model will be operating on when performing inference. However, in our case the model should learn to perform scheduling on a compute cluster and running a cluster of a significant size and letting it respond in realtime to the decisions made by the model is not feasible. Therefore, we have come up with a way to simulate a cluster that is able to run and respond in faster than realtime.
With the DECICE project we have set out to develop a machine learning (ML)-based scheduler that is able to outperform heuristic schedulers in terms of finding better workload placements on a given compute cluster with regards to performance, reliability and energy efficiency. Furthermore, our ML-based scheduler should be able to act across a heterogeneous compute landscape consisting of cloud, edge and HPC nodes.
Developing such a scheduler requires solving multiple challenges, one of which is to answer the question: “How can we train and evaluate a ML scheduler model?”
Our solution should enable us to train one or more scheduler models at the same time without having to run a real cluster for each model. Setting up real clusters as an initial trainings environment is not feasible for us as it is expensive to run that many clusters each with a non-trivial amount of nodes then some users would be required to use each cluster to generate some required scheduling decisions for our model to work with and at last we would need a way to compare the scheduling decision made by the model with the “correct” decision.
Simulated Training Environment
To solve this issue, we came up with a simulated approach that uses artificial data as input for the scheduler with known optimal scheduling decisions. This approach enables us to request scheduling decisions from our model multiple times per second. For each decision the model also receives a system state in the form of a Digital Twin (DT), which does not need to be related to previous system states as the model only sees each scheduling request and system state in isolation.
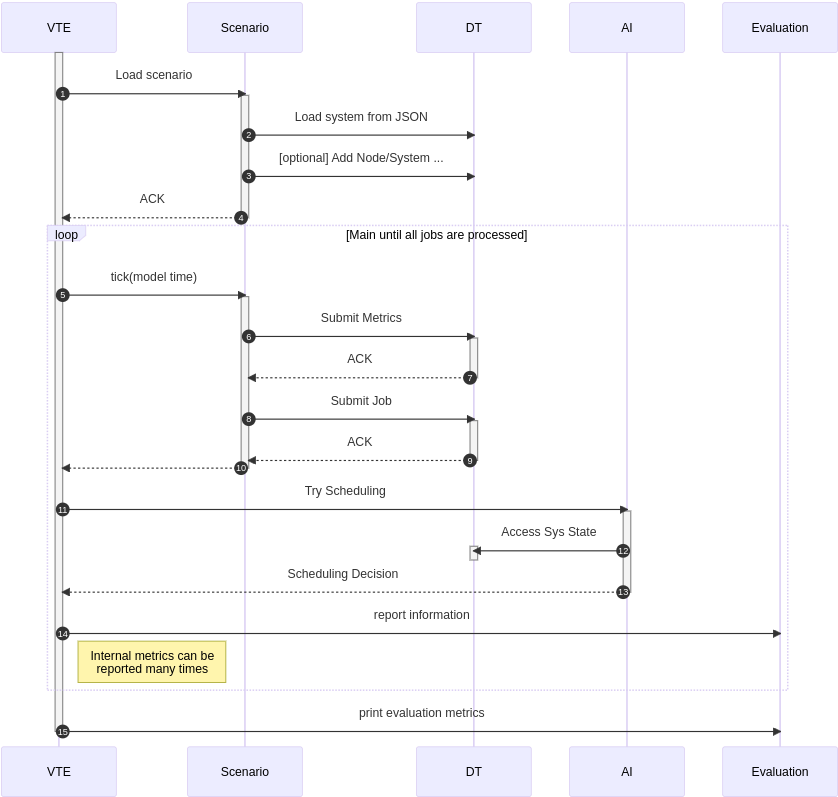
The figure below depicts the virtual training environment (VTE) we have designed. The VTE component serves as the main process for the trainings environment. The scenario is a series of system states in the form of artificial metrics, which also includes a queue of scheduling requests. The Digital Twin (DT) is updated when it receives metrics, in this case, it receives new metrics from the current scenario. The ML scheduler model, marked here as AI, is asked to perform scheduling decisions for every update to the DT and its decisions are recorded such that they can be evaluated and used to direct the training of the model.
AI Scheduling in a Real Cluster
When putting the scheduler model to work in a real cluster, we replace the VTE and Scenario components with the cloud manager (CM) and the metrics system (MS) respectively. Furthermore, instead of only reporting the scheduling decisions made by the model to an evaluation system, they are also sent to the underlying Kubernetes (K8s) platform such that the scheduling decision can be realized. This process is shown in the figure below.
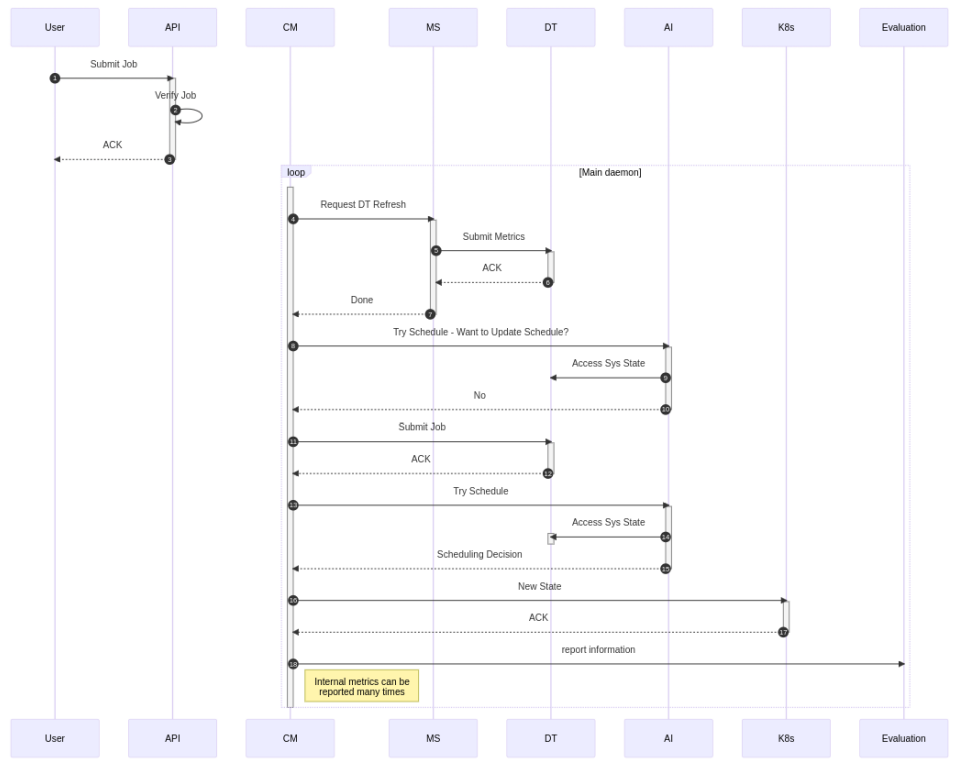
Due to the design of the scheduling system, our solution is mostly agnostic regarding the actual scheduling platform. For now we are focusing on Kubernetes as the orchestration platform but it could also be replaced by another platform. In addition to this, Prometheus is evaluated as a metrics system to store time series data and provide it to the Digital Twin.
All that is required from the underlying platform is metrics via metrics system to construct the digital twin from and a translation layer to integrate the AI scheduler as a scheduler that can be called from the orchestration platform and that can deliver scheduling decisions that are understood.
Conclusion
In this post we have discussed how simulation can enable training of ML models for scheduling of workloads on compute clusters. Furthermore, we have shown a design that allows for faster than realtime training by using artificial trainings data and by isolating the model under training from the system state of previous scheduling decisions. We know that the design leaves some questions open and we look forward to addressing these concerns once we put the design into action.
Author: Jonathan Decker
Links
https://www.uni-goettingen.de/
Keywords
AI, AI-scheduler, machine learning, ML, Digital Twin, virtual training environment